핵심어 : char는 byte(8비트) 단위의 처리를 규정한다. 8비트 정수형 변수
char는 C에서 8비트 정수형 변수이다. 원래의 문자라는 말은 정수형의 부분집합일 뿐이다. 따라서 단지 'char는 문자'라는 말은 한정된 개념만을 설정한 것이므로 잘못된 개념이다. int와의 차이는 정보의 비트수가 다를 뿐이다. 모든 체계는 int와 같다. 처음에 B언어를 설계한 개발자가 이것을 char라고 표현 했을 뿐이다. 그래서 지금은 byte라는 말로 사용하려는 경향이 있다.
typedef unsigned char BYTE;
이런식이다.
C에서 정수는 부호의 경우 2의 보수체계을 사용하므로 char역시 마찬가지 이다.
8비트 정수 : char
모든 CPU
변수선언 값의 범위 최소값 -1 0 최대값
char ch; -128 ~127 0x80 ~ 0xFF ~ 0x00 ~ 0x7F
unsigned char 0 ~ 255 0x00 0x00 0xFF
8비트CPU
int idt; 0x8000 0xFFFF 0x0000 0x7FFF
unsigned int 0x0000 없음 0x0000 0xFFFF
32비트 CPU
int idt; 0x80000000 0xFFFFFFFF 0x00000000 0x7FFFFFFF
unsigned int 0x00000000 없음 0x00000000 0xFFFFFFFF
C의 문 자형
한글의 문제는 조합형과 완성형이라는 또 다른 문제가 있다. 개인적으로 조합형이 컴퓨터와 잘 맞다고 생각하지만 국제적인 문자체계인 영어, 프랑스어 등의 체계와는 다른 언어의 방식이라고 볼 수 있고, 오히려 여기에 맞추어 완성형이 표준화 되었다. KS-5601이라는 체계가 한글 체계화 된 것이다.
따라서 현재의 C는 초기부터 ASCII, KS-5601이 어떻게 처리되는지부터 생각할 수 있다. 그런데 이 두 문자체계는 비트 수부터 다르다. ASCII는 8비트, KS-5601 및 UNICODE는 16비트이다. 그런데 C의 char라는 변수는 기본적으로 8비트를 처리 단위로 한다. 따라서 한글의 한글자를 char 변수에 담을 수 없고 어래이에 담아야 한다.
char asciich;
asciich = ‘A’;
이것은 가능하지만
char ksch;
ksch = ‘송’;
이것은 불가능하다. ‘송’은 16비트이기 때문이다.
KS-5601 완성형 코드 예
홍 : 0xC8AB
길 : 0xB1E6
동 : 0xB5BF
따라서 이것을 사용하려면
char ksch[3];
strcpy(ksch,”송”);
와 같이 사용하여야 한다. 실제로 ksch는 3바이트라 레지스터로는 동시에 처리할 수 있지만 char는 한번에 1개의 바이트의 처리가 기본적인 개념적 약속이기 때문에 함수를 사용하여야 한다.
컴파일러는 char 변수관련 프로그램은 8비트 기계어 코드로 선택하여 컴파일 한다.
따라서 2바이트 이상의 char는 다음 함수와 같은 코드가 필요한 것이다.
void strcpy(char *dest, char *src)
{
while (*src) {
*dest++ = *src++;
}
*dest = (char) 0;
}
char ksch[3];
ksch = ”송”;
이와 같은 코드에서는 불가능하다. 여기서의 ‘=’은(C에서는) 한번의 기계어 코드로 옮길 수 있는 단위만을 처리 한다. 그런데ksch는 이미 char로 문자단위 처리로 약속되어 있는 것이기 때문에 1바이트 단위만으로 메모리로부터 read/write 할 수 있는 것이다.
CPU의 char 및 16,32 비트 억세스 구조
‘=’을 정확히 이해하기 위해서는 CPU의 메모리 억세스를 이해 해야 한다. 보통의 32비트 컴퓨터라도 데이터를 억세스할 때는8,16,32비트 단위로 선택적으로 access 할수 있다.
어셈블러에 보면 이것을 확인할 수 있다. 또 한번 C가 기계어와 얼마나 가까운가를 생각해 볼 수 있는 문제이다.
Intel 80x86계열 (IA32)
mov al,16 - 8비트
mov ax,16 - 16비트
mov eax,16 - 32비트
mov al, BYTE PTR _a
mov BYTE PTR _buff, 0 ; buff = (char) 0;
mov ax, WORD PTR _a
mov eax, DWORD PTR _a
모토롤라
move.b d0,$03002330 - 8비트
move.w d0,$03002330 - 16비트
move.l d0,$03002330 - 32비트
이것은 실제로 CPU에서 처리되는 양상은 주소체계가 다르면서 몇 가지 문제가 발생하기도 한다. 실제로 통신에 의해 데이터가 전송되면 int와 결합하여 타입 변환되고 이것이 문제를 발생하기도 한다. 여러가지 타입변환이 이루어지는 프로그램에서는 숫자가 다르게 나타나기도 하지만 단순한 8비트 처리한다면 그리 문제가 되는 경우는 적다. 어째든 어떻게 문제가 발생할지 모르는 일이므로 항상 설계에 고려하여야 한다.
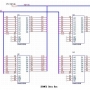
이 메모리 상의 data bus의 배치는 다음과 같은 회로로 나타낼 수 있다. 이 회로는 SRAM(Static RAM)이지만 DRAM 역시 마찬가지 이다. 이것은 CPU가 바이트 단위의 처리를 포기하지 못하는 한 나타나는 현상이기 때문이다.
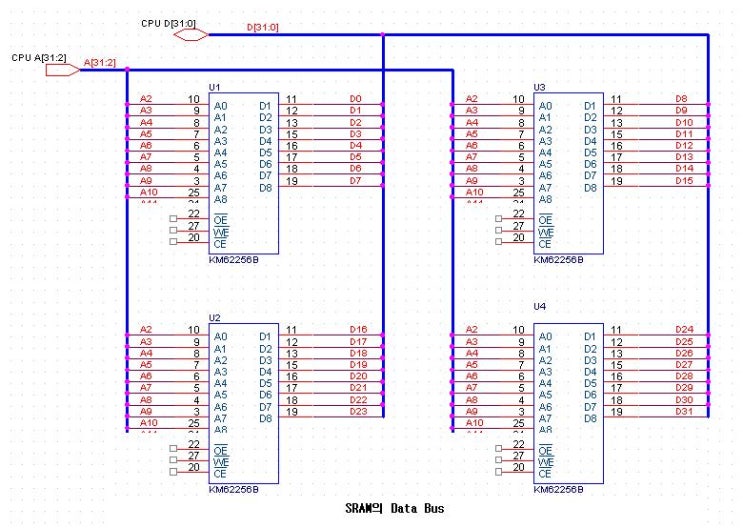
위의 회로에서 CPU와의 관계를 다시 한번 도식화 하면 다음과 같다.
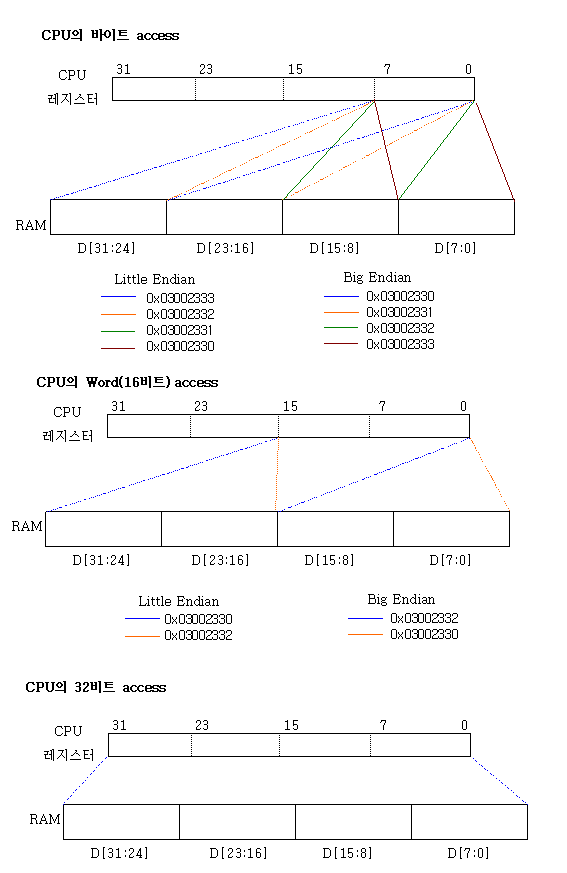
각 비트 별 CPU의 억세스를 보는 이유는 실제로 C을 프로그램 한다는 것은 어떤 의미든 CPU의 동작과 밀접한 관계가 있고 이것을 모르면 Debug가 힘들어 지는 경우가 있다. 또한 CPU을 직접 설계하는 개발자라면 C로 구동 프로그램을 작성해야 하는데 이것의 개념을 모르면 C의 활용은 불가능 하다.
1. Byte 단위의 access
char ch;
char a; // a의 &a = (char*) 0x03002330;
ch = a;
mov al, BYTE PTR _a à a의 값을 읽어오는 과정임. – Direct Address Mode
위와 같은 상황에서 Intel 80계열에서 이와 같은 기계어 명령이 실행되면
RAM의 0x03002330번지의 데이터가 data bus D[7:0 ]의 신호선을 타고 CPU에 입력되면 CPU의 AX 레지스터 중에 AL, 즉 LSB로 들어간다. 레지스터 al의 값을 다시 ch에 넣기 위해
mov BYTE PTR _ch, al à ch에 값을 넣는 과정임. – Direct Address Mode
만약 char a;의 메모리 위치가 0x03002331 이라면
mov al, BYTE PTR _a
는 data bus D[15:8 ]à AL (Direct Address Mode)가 된다.
2. 16비트 단위의 access
char가 아니고 short int로 16비트가 설정 된 변수라면
short int a; // a의 &a = (short int*) 0x03002330;가 할당 되었음.
short int b;
mov ax, WORD PTR _a
이 기계어 코드 한 개가 실행되면 RAM의 0x03002330번지와 0x03002331의 데이터가 data bus D[15:0 ]의 신호선을 타고 CPU에 입력되면 CPU의 AX에 저장 된다.
D[15:8 ]à AH
D[7:0 ] à AL
물론 모토롤라의 68000계열이라면 move.w D0,$0x03002330가 실행되면
D[15:8 ]à D0 (7:0 )
D[7:0 ] à D0 (15:8 )
로 들어 간다.
16비트로 access 할 때는 주소값 끝의 A0는 반드시 0으로 설정되어야 한다. 따라서 주소값을 프로그램으로 &a 값을 찍는다면0x03002330이지 0x03002331는 안된다. 이것은 다시 강조하면 CPU가 WORD로 한번에 읽거나 쓰는 것이다. 이것의 보장은 컴파일러가 알아서 한다.
예를 들어
int a;
char ch;
int idata[100];
위의 변수 3개를 배치할 때, 어래인지 문제가 적용된다.
컴파일러 만다 어떤 것은 idata -> ch -> a 순으로 메모리 번지를 증가하면서 배치하고 어떤 것은 a -> ch -> idata 순으로 배치 하므로 후자를 생각 해 본다.
첫번째 int a;가
int a; : 0x001002000이라면
char ch; : 0x001002004 번지 인데 1바이트 이다.
idata[0] : 0x001002008 번지로 점프할 수 밖에 없다.
이것은 ch의 주소 값 0x001002004은 한바이트 이면 ch는 만족하지만 idata의 초기 배치할 때, 시작은 반드시 주소의 A1,A0가 모두 00이어야 하므로 이 같은 결과를 초래 한다.
주소 값이 이와 같이 배치되지 않으면 CPU는 한 개의 int 처리를 위해 여러 개의 기계어가 필요하고 이렇게 하면 CPU의 비트 수를 늘릴 이유가 없어진다.
물론 32비트 CPU 말고 8bit,16비트라면 int을 처리하기위해 여러 번의 access가 이루어 져야 하므로 상관은 없을 것이다.
예를 들어 Z-80은 int가 주로 16비트인데
int ival;
을 배치 했다면 이 값을 int을 16비트를 보장하기 위해 2개의 레지스터로 처리 할 것이다.
BC, DE, HL 등으로 처리하지만
&ival = 0x2003이라고 할 때
LD B,2003H
LD C,2004H
이렇게 2번 읽어 와야 한다.
이 어래인지 문제는 struct의 내부에서 배치 할 때 예외가 아니다.
struct TestInt {
int a;
char ch;
int idata;
};
struct TestInt tint;
일 때 tint 역시 마찬가지의 원리의 지배를 받고 있어 sizeof(struct TestInt) 한다면 길이를 확인 할수 있을 것이다.
char 변수와 array
char 변수와 array에 대해 생각해 보자.
한 문자는 무조건 한 바이트, 이것이 기본적인 char 의미이다. 그리고 CPU에서도 처리하는 단위는 한 바이트 단위의 처리를 한다는 것이 기본이다. 여기에서 한 바이트 만으로 정보를 처리 한다는 것은 불가능이다. 세상의 많은 일은 여러 바이트로 이루어지고 이것을 처리하는 컴퓨터는 여러 바이트를 저장하고 처리 해야 한다. 여기서 말하는 여러 바이트는 한바이트 한 바이트 문자가 모여 이루어지며 이것을 string 이라고 한다. 즉, 여러 문자가 string이다. 결국 string이라는 변수를 char와 독립해서 따로 만둘 필요 없이 char의 array가 string이 되는 것이다. 문자의 string은 문자가 연속적으로 배치되어 있는 것을 말한다. 이것을 CPU 입장에서 보면 메모리에 정해진 처음위치부터 주소가 1씩 증가하면서 배치 되어 있는 것을 말하는 것이다. 물론 모든array가 메모리 상에 끊김 없이 연결되어 있음은 마찬가지이다. 이것은 중요한 의미를 갖는데 포인터로 처리할 때, 자동으로 증가하는 구조라든가 하는 등으로 주소 계산법이 여기에서 결정되는 것이다.
char name[20];
이것은 string을 처리하기 위한 것인데, 20바이트를 메모리상에 연속적으로 확보하는 것이다. 이런 상황에서 C는 바이트 단위로 처리하여 데이터를 저장하는 것이다.
그러면 ASCII와 한글의 방식은 어떤가?
char name[20];
strcpy(name, “Hello”);
이런 상황에서 배치는
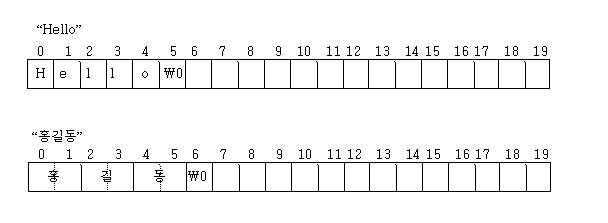
string의 끝은 숫자 0으로 넣어 문자의 끝임을 나타낸다. 따라서 C로 작성하는 모든 코딩은마지막 코드가 0임을 정하고 프로그램되어 졌고, 되고 있고, 되어질 것이다. 0 뒤는 어떤 숫자 코드든 무시하면 된다.
char array의 index는 0부터 시작한다. 그러나 array의 사이즈는 0이 기준이 아니라 1이다.
위의 변수 name[20]은 20 바이트로 0~19로 그 위치를 나타낸다.
한글은 2바이트가 한 글자 이므로 위와 같이 배치가 됨을 알아야 처리가 가능하다. 그러면 한글과 한글이 아니라 ASCII는 어떻게 구별하는가?
이것은 KS-5601에서 문자를 배치할 때, 몇 가지 특징을 가지고 있다.
1. 모든 코드의 맨 앞 비트는 ‘1’ 이다.
2. 한글문자 코드 중 두 바이트는 0이 없다.
따라서 프로그램할 때, 고려해야 한다.
char name[20];
strcpy(name, “홍길동 ”);
for (cnt = 0; name[cnt] != 0;cnt++) {
if (name[cnt] & 0x80) { // true면 한글
. . .
}
. . .
}
지금까지의 언어적인 차이와 다국어 지원을 하기 위해서는 한 문자를 한 바이트로 취급하는 것은 문제가 있다. 따라서 이를 해결하기 위해 UNICODE가 등장하였다. UNICODE는 16비트가 처리 단위 이다. 이것은 자바 역시 마찬가지로 16 비트의 UNICODE을 사용한다.
VisualC++에서는 다음과 같은 wchar_t가 추가 되었다.
wchar_t *wmsg = L"abc";
메모리 배치를 보면 다음과 같이 16진수로 나타낼 수 있다.
L"abc" : 0061 0062 0063 0000
만약 이 변수의 내용을 일반적인 ‘char msg[];’ array로 보면
61 00 62 00 63 00 00 00 - 한글자 정도는 볼수 있음.
여기서 주의 할 것은 ASCII 코드를 8비트에서 16비트로 늘리면서 MSB쪽에 0x00을 추가 하였다.
char의 메모리 위치와 주소값 계산 방법
char는 변수가 위치한 메모리에 순차적으로 나열 되어 있는 형태를 의미하는데, 실제적인 메모리의 구조를 통해 보면
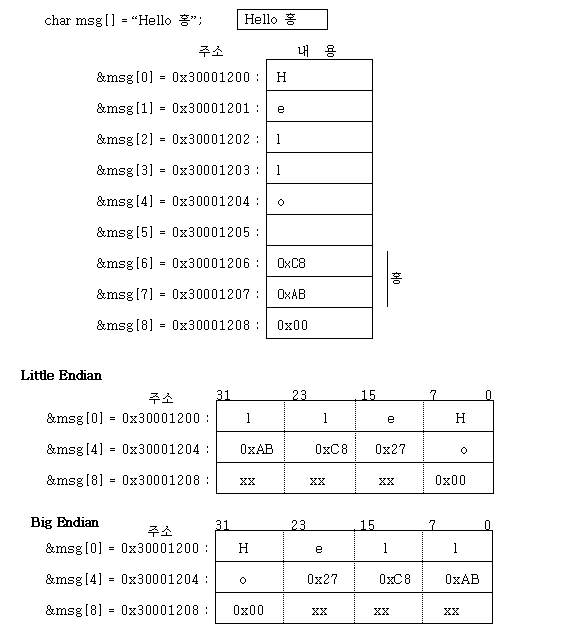
위의 char의 메모리 구조가 CPU 마다 다르지만 32비트 컴퓨터는 일반적으로 위의 2가지 방식에 의해 string이 배치 된다. 이것은 CPU의 억세스 구조에서 본 것으로부터 연관을 가지고 개념을 잡아야 한다.
이제는 char의 포인터와 주소 계산을 생각해 본다. 이것은 기본 단위가 바이트 이기 때문에 주소 역시 1씩 증가함을 기본으로 한다.
char msg[] = “hello 홍”;
이라고 할 때, 위의 그림은 msg의 시작 번지가 0x30001200 이었다. 이것의 표현은 다음과 같은 여러가지를 생각할 수 이다.
우선 특정 위치의 문자를 정의는 상식적으로
msg[0] = ‘H’;
msg[1] = ‘e’;
등으로 표현 가능하다. 이때의 주소 값 계산 과정은 컴파일러가 하는 과정은
msg[index]
=> msg의 값을 linker에 의해 결정된다. 여기서의 예가 0x30001200 이므로
=> msg + sizeof(char) * index 에 의해
=> 0x30001200 + 1 * index
=> index가 1이면, 0x30001200 + 1 * 1 = 0x30001201 이다.
[]을 이용한 주소 값 변환은 이것만 알면 된다. 다른 int, struct 형의 변수도 마찬가지의 규칙을 갖는다.
잠간 옆길로 세면
int 형의 주소 계산법
int idata[100];
idata[index]
=> idata 의 값을 linker에 의해 결정된다. 여기서도 0x30001200에 배치되었다고 가정
=> idata + sizeof(int) * index 에 의해
=> 0x30001200 + 4(바이트) * index
=> index가 1이면, 0x30001200 + 4 * 1 = 0x30001204 이다.
struct 형은
struct testst {
int no;
char sex;
int age;
};
struct testst stdata[100];
stdata [index]
=> stdata 의 값을 linker에 의해 결정된다. 여기서도 0x30001200에 배치되었다고 가정
=> stdata + sizeof(struct testst) * index 에 의해
=> 0x30001200 + 0xC(12 바이트) * index
=> index가 1이면, 0x30001200 + 0xC * 1 = 0x3000120C 이다.
이제는 포인트 표현과 주소와의 관계는 삼각관계이상으로 복잡하지만 원리만 알면 가능하다.
char data[100];
char *pch;
이라고 했을 때, 이 변수의 의미는 문자형 을 가르킬 수 있는 메모리 공간을 확보하라는 의미 이다. 이 말은 메모리 공간은 주소값으로 저장되므로 CPU가 원하는 길이가 필요하다.
80X86의 32 비트 CPU 및 32비트의 대부분은 32비트의 주소값을 갖는다. 이것은 중요한 의미이지만 다음을 넘기고 우선 포인터의 길이는 CPU가 결정되면 어느 정도는 결정 된다는 사실이다.
즉, pch 위에서 계산한 주소값의 예처럼 0x30001200의 값만 넣으면 되는 변수이기 때문에 공간은 4바이트 이다.
pch = data;
여기서 array의 index 표시를 하지 않으면 [0]을 의미하고 이것의 포인터를 나타낸다.
pch = &data[0];
와 같은 코딩이 된다.
char data[100][10];
이라면
pch = data[3]; => &data[3][0]을 말한다.
와 같은 코딩이 된다.
그림의 예로 생각하면
char *pch;
pch = msg;
*pch = ‘H’;
라고 하면 처음에 &msg[0]로 넣어졌기 때문에 0x30001200을 말한다.
pch++;
라고 코딩하면 이것은
pch = pch + sizeof(char);로 볼 수 있고
pch = pch + 1;이 되어 0x30001201 이 된다.
여기서 +의 의미는 1을 더한다기 보다는 포인터의 주소값을 다음으로 넘긴다는 이야기 이다. 이 말은 단순히 1을 더 한다고 생각하면 다른 변수의 주소 값을 더하는 것과 혼동이 되는 것이다. 예를 들어
int data[100];
int *pdata;
pdata = data;
*pdata = 10;
pdata++;
여기서의 pdata++의 주소는 다음과 같이 char 포인터와 같다.
pdata = pdata + sizeof(int);로 볼 수 있고
pdata = pdata + 4;이 되어 0x30001204 이 된다.
struct도 마찬가지로 sizeof(struct testst) 처럼 증가함을 이해 해야 한다.
만약 char 포인터가 다음과 같다면
char msg[100];
int ip;
char *pch;
ip = 2;
pch = msg;
pch += ip;
라고 할 때, pch = pch + size(char) * ip가 된다.
=> 0x30001200 + 1 * 2 => 0x30001202가 된다.
int난 struct는 sizeof(int)만 바꾸면 계산법은 같다.
이번에는 다음과 같은 방식의 표현 방식을 생각해 본다.
*(pch+ip) = ‘a’;
라고 한다면
우선 pch+ip을 구하면 pch + siseof(char) *ip가 되고 값은 0x30001200 + 1 * 2 => 0x30001202가 되고 이 주소에 ‘a’을 넣는다.
지금까지 복잡한 계산의 기본이 되는 원리가 있다면 위의 여러가지를 부분별로 이해할 필요가 없을 것이다. 이것은 간단히
포인터 변수 연산은 그것의 취급 단위에 의해 변수의 초기 주소부터 산술 연산이 이루어 지고 있음을 의미 한다.
여기서 한 가지 더 생각해야 특징한 예약어 와의 주소 변환 과정을 생각할 것이 있는데 그것이 바로 void 포인터 이다.
char msg[100];
void *pvoid;
pvoid = (void *) msg;
void는 특이한 형태인데 아무것도 모르는 상황의 의가 있다. 위의 상황에서 다시 다음과 같은 상황을 생각하자.
*pvoid = ‘a’;
라고 하면 어떻게 되는가? 이것은 *pvoid가 말하는 위치는 0x30001200으로 주소는 알 수 있는데, 이것이 ‘a’가 들어갈 때 문제가 생긴다. void란 말에서 알 수 있듯 시 값을 넣어야 할 형태가 모른다는 문제가 있다. 이것은 CPU가 8비트로 해야 할지, 16,32비트로 할지 알수 없는 상황이 되어 버린 것이다. 그런데 어떻게 포인터 변수는 가능 할까? 이것은 CPU가 포인터는 무조건 주소값을 갖는 공간만을 나타내는 것이므로 이미 CPU에서 결정되어 있어서 32비트의 주소체계을 갖는다면 32비트만 넣을 공간만 확보하면 된다는 것을 알 수 있는 것이다. 그래서 굳이 이것을 하려면, 아니 필요에 따라 할 필요가 있을 때 다음과 같이하면
*((char*) pvoid) = ‘a’;
이러면 주소는 알고 있고 access 타입만을 알 수 있으면 되므로 이제는 아 8비트를 넣으면 되는 구나를 결정할 수 있는 것이다.
이것 뿐만 아니라 다음과 같은 상황을 보면
char msg[100];
void *pvoid;
pvoid = (void *) msg;
pvoid++;
‘pvoid++’의 의미는 위의 원리을 이용해 주소값을 계산 한다면
pvoid = pvoid + sizof(void)
이렇게 해야 하는데 void을 모르는 어떤것이기 때문에 sizeof가 길이를 계산할 수 없다. 따라서 이것의 컴파일은 불가능 하다.마찬가지로 pvoid+ip, 등의 구조도 불가능하다.
만약 2차 배열의 주소 값 법은
#define SZ_LEV1 100
#define SZ_LEV0 10
char data[SZ_LEV1][ SZ_LEV0];
char *pch;
pch = data;
int x,y;
이 상황에서 data[y][x]을 지정하고 싶으면
*(pch + y*SZ_LEV0+x) = ‘a’;
가 가능하다. 이 때의 주소는
pch + sizeof(char) * [ y*SZ_LEV0+x ]가 된다.
x = 1, y = 2 일때
0x30001200+1*(2*10+1) = 0x30001200 + 21 = 0x30001215
char 변수의 몇 가지 특이 사항
1. 초기값을 갖는 전역변수
char msg[] = “Hello”;
의미는 int의 초기값과 같은 구조로 처리 된다. 이것은 msg 변수 초기값을 갖는 변수 영역에 할당하고 프로그램 실행 전에 “hello”라는 string이 전송되고 프로그램 실행 되는 것이다. 그러나 다음과 같은 코드를 생각해 보자.
char msg[100];
msg = “Hello”;
와 같은 코딩은 불가능하다. 이것은 msg라는 변수영역에 string을 복사하는 것이다. 위에서 언급 했듯이 ‘=’이라는 기본적으로 CPU가 한번의 기계어 동작에 의해 전송되는 것을 의미 하기 때문이다.
#include "stdafx.h"
char msgh[100] = "Hello";
char msg[100];
void pmsg()
{
msg = "Message";
char *pmsg = "Message";
printf(pmsg);
}
------- Configuration: ClOpt - Win32 Release ---------------------–
Compiling...
fchar.cpp
D:...fchar.cpp(9) : error C2440: '=' : cannot convert from 'char [8]' to 'char [100]'
There is no context in which this conversion is possible
Error executing cl.exe.
ClOpt.exe ‐ 1 error(s), 0 warning(s)
이것은 Visual C++로 컴파일 한 것인데, 만약 빨간색의 ‘msg = "Message";’을 제거 하면 error가 사라지고 문제가 없음을 확인할 수 있다.
이에 비해 이것을 포인터로 바꾸면
char *pmsg;
pmsg = “Hello”;
는 가능한데 여기서의 ‘=’은 string “hello”가 있는 주소 값을 pmsg 변수 넣는 것이므로 위의 내용에 위배되지 않는다.
char msg[100];
char *pmsg;
char *pdmsg;
void prtmsg()
{
pmsg = "Message";
pdmsg = msg;
while (*pmsg) *pdmsg++ = *pmsg++;
*pdmsg = (char) 0;
printf(msg);
}
_BSS SEGMENT
_msg DB 064H DUP (?) ; char msg[100];
_pmsg DD 01H DUP (?) ; char *pmsg;
_pdmsg DD 01H DUP (?) ; char *pdmsg;
_BSS ENDS
PUBLIC _Message ; `string'
EXTRN _printf:NEAR
; COMDAT _Message
_DATA SEGMENT
_Message DB 'Message', 00H ; `string'
_DATA ENDS
; COMDAT _prtmsg
_TEXT SEGMENT
_prtmsg PROC NEAR ; prtmsg, COMDAT
mov al, BYTE PTR _Message
mov ecx, OFFSET FLAT:_msg ; msg
test al, al
mov DWORD PTR _pmsg, OFFSET FLAT:_Message ; pmsg, `string'
mov DWORD PTR _pdmsg, ecx ; pdmsg
. . .
위의 어셈블리에서 string “Hello”는 정해진 위치(_DATA SEGMENT)에 string의 데이터 형태로 존재하고 이것의 포인터가 ‘pmsg = "Message";’에 의해 포인터 값이 변수의 address에 저장 된다. 여기서 다시 한번 강조하면 ‘=’이 string 전체를 복사하는 것이 아니라는 것이다.
2. 주소 변환 시 포인터 변수와 []변수와는 같은 것이다
char data[100];
char *pch;
pch = data;
pch[0] = ‘H’; pch[1] = ‘e’;
와 같은 표현이 가능하다.
이것은 컴파일러가 기계어 코드를 생성할 때, 같은 원리로 동작함을 알 수 있다.
pch[1] => pch+1과 같고 => 주소값은 pch의 주소값 + sizeof(char)*1
=> 0x30001200+1*1 = 0x30001201
[]을 사용 하는 함수의 예를 들면
void strcpy(char *dest, char *src)
{
int cnt;
for (cnt = 0;src[cnt];cnt++) {
dest[cnt] = src[cnt];
}
dest[cnt] = (char) 0;
}
이 함수 같은 기능의 포인터를 이용한 프로그램으로 한다면
while (*src) {
*dest++ = *src++;
}
두 프로그램의 기능은 같지만 컴파일 코드는 많은 차이가 있다.
‘dest[cnt] = src[cnt];’에서 ‘dest[cnt]’는
dest의 시작주소 + sizeof(char)*cnt
와 같은 복잡한 계산을 한다면
*dest++는 ‘*dest’와 dest++의 결합으로
주소 계산없이 바로 문자를 넣고 포인터의 주소값을 sizeof(char) 만큼 만 증가하면 된다.
위의 2개의 차이는 프로그램 상에서 어느 것을 선택 코딩 하느냐에 따라 실행 능력에 많은 영향을 미친다는 것에 주목해야 한다.
char의 정수형 의미
char는 문자를 취급하는 변수인데, 이것의 의미는 무엇인가. 이것과 관련해 문자 코드란 무엇인가와 연결되어 있다. 이 변수 타입과 관련해 초기의 도입목적은 문자를 취급 한다는데 있지만 실제 사용과 응용의 측면을 볼 때 반드시 문자만을 취급하는 개념을 넘어 선다. 오히려 char는 byte 단위의 처리를 의미 한다. 즉, CPU가 메모리나 레지스터를 억세스 할 때, byte 단위로 이루어 졌다면 모두 char을 사용하는 것이다. 이 말은 다시 말해 숫자도 한 바이트 내에 있다면 char 인 것이다. 따라서 char는 바이트로 처리하는 단위를 말하며, 이것은 정수형 과 구별되지 않고 같은 구조로 이루어 지는 것이다.
소문자를 대문자로
char ch;
if (ch >= ‘a’ && ch <= ‘z’)
ch = ch – ‘a’ +’A’;
여기서의 연산은 ch 변수의 값이 레지스터로 전송되고 다음은 산술연산 중 +,‐을 이용해 대문자로 바꾼 것이다.
여기서 바꾸는데 사용한 코드 ‘ch = ch – ‘a’ +’A’;’는 다음과 같이 기계어로 개념화 할 수 있다.
sub.b r0, 32 ; ‘A’‐ ‘a’=> ‐32
intel 80x86은
sub al, 32
이 기계어 코드에서 ch 변수를 int로 바꾸면 다음과 같이 기계어가 처리 단위가 바뀌고 나머지는 CPU의 연산 체계가 같음을 알수 있다.
int ch;
if (ch >= ‘a’ && ch <= ‘z’)
ch = ch – ‘a’ +’A’;
sub.l r0, 32
80x86 : sub eax, 32 ; 00000020H
여기서 char가 CPU에서의 처리 단위을 규정함을 알 수 있다.
다음 프로그램에서 다시 한번 고려 해 본다.
char cval1;
char cval2;
unsigned char ucval1;
unsigned char ucval2;
int main(int argc, char* argv[])
{
cval1 = 'a';
cval2 = cval1 + 0x60;
ucval1 = 'a';
ucval2 = ucval1 + 0x60;
//. . .
}
이 프로그램을 기계어로 컴파일하면 다음과 같다. 컴파일러는 VC++ 6.0이다. 컴파일마다 기계어 코드가 달리 나오나 원리적인 문제를 학습하는데 문제가 없다.
전역변수는 _BSS segment에 할당하고 다음과 같이 코딩 된다.
PUBLIC _cval1 ; cval1
PUBLIC _cval2 ; cval2
PUBLIC _ucval1 ; ucval1
PUBLIC _ucval2 ; ucval2
_BSS SEGMENT
_cval1 DB 01H DUP (?) ; cval1
ALIGN 4
_cval2 DB 01H DUP (?) ; cval2
ALIGN 4
_ucval1 DB 01H DUP (?) ; ucval1
ALIGN 4
_ucval2 DB 01H DUP (?) ; ucval2
_BSS ENDS
; cval1 = 'a'; 'a' == 97 (ASCII 코드)
mov BYTE PTR _cval1, 97 ; cval1, 00000061H
; cval2 = cval1 + 0x60;
movsx eax, BYTE PTR _cval1 ; cval1
add eax, 96 ; 00000060H
mov BYTE PTR _cval2, al ; cval2
; ucval1 = 'a';
mov BYTE PTR _ucval1, 97 ; ucval1, 00000061H
; ucval2 = ucval1 + 0x60;
xor eax, eax
mov al, BYTE PTR _ucval1 ; ucval1
add eax, 96 ; 00000060H
mov BYTE PTR _ucval2, al ; ucval2
코딩 부분을 보면 부호가 있는 char을 계산하는 것이다.
; cval1 = 'a'; 'a' == 97 (ASCII 코드)
mov BYTE PTR _cval1, 97 ; cval1, 00000061H
_cval1의 영역에 'a'을 넣고
다음의 char 연산을 계산하기 위해 다음과 같이 기계어로 바뀐다.
; cval2 = cval1 + 0x60;
movsx eax, BYTE PTR _cval1 ; cval1
byte을 32비트의 레지스터로 변환 옮기기 위해 movsx을 사용 하였다. 이것은 부호를 유지하기 위해 이 기계어로 컴파일 된 것이다.
add eax, 96 ; 00000060H
32비트로 계산이 되고 이것의 한 바이트만 cval2에 전송된다.
mov BYTE PTR _cval2, al ; cval2
이 기계어 코드가 말하는 것은 부호가 있는 char 변수는 레지스터로 계산할 때, int와 개념적 차이가 없음을 나타 낸다.
이와 비교하기 위해 unsigned char 의 기계어 부분을 살펴보면
; ucval1 = 'a';
mov BYTE PTR _ucval1, 97 ; ucval1, 00000061H
; ucval2 = ucval1 + 0x60;
xor eax, eax
우선 32비트를 사용하기 위해 EAX 레지스터를 지운다. 그리고는 다음 줄과 같이 8비트 만을 전송한다.
mov al, BYTE PTR _ucval1 ; ucval1
이러면 32비트의 앞부분이 0으로 채워 지면서 unsigned 가 유지 된다.
add eax, 96 ; 00000060H
32비트로 계산을 하고
mov BYTE PTR _ucval2, al ; ucval2
ucval2에 저장 한다.
위에서 VC++6.0은 char을 계산할 때 int로 변환하여 계산함을 볼수 있고 int형의 2의 보수 체계를 통한 연산을 유지함을 알 수 있다.
기계어로 바꿀 때, 컴파일 마다 차이가 있는데 이번에는 차이만을 비교하기 gcc로 컴파일 해 본다.
;char cval1;
;char cval2;
;unsigned char ucval1;
;unsigned char ucval2;
.globl _cval1
.bss
_cval1:
.space 1
.globl _cval2
_cval2:
.space 1
.globl _ucval1
_ucval1:
.space 1
.globl _ucval2
_ucval2:
.space 1
; cval1 = 'a'; 'a' == 97 (ASCII 코드)
movb $97, _cval1
; cval2 = cval1 + 0x60;
movzbl _cval1, %eax
addb $96, %al
movb %al, _cval2
; ucval1 = 'a';
movb $97, _ucval1
; ucval2 = ucval1 + 0x60;
movzbl _ucval1, %eax
addb $96, %al
movb %al, _ucval2
VisualC++의 컴파일 방법과는 다른데 여기서는 EAX 레지스터의 값을 변환 할 때, unsigned이든 그냥 char 이든 32비트로 확장하고 않고 8비트의 연산을 통해 부호를 처리함을 볼 수 있다.
char의 포인터와 포인터 계산 그리고 비교 이해
포인터는 CPU가 결정되면 주소 값을 취급하기 위한 바이트 수는 결정된다. MCU의 경우는 section에 따라서도 주소값을 취급하는 바이트는 다른 수 있다. 80x86등의 32비트는 주소값 역시 32비트 이다. 그런데 이 주소값을 계산할 때가 생기는데 CPU의 레지스터의 값을 ALU을 통해 계산되는 방식을 사용 한다.
다음은 string중에서 처음 이름을 다른 데이터와 분리하여 이름만을 추출하는 프로그램 예을 통해 이해해 본다.
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
char buff[1024] = "Kim 12 23 43";
char name[100];
int main(int argc, char* argv[])
{
char *dstr;
char *sstr;
char *nstr;
// buff에서 SPACE을 기준으로 다음 인수를 찾는다.
nstr = buff;
while (*nstr && *nstr != ' ')
nstr++;
// 이번에는 분리된 곳까지 짤아 이름을 분리한다.
sstr = buff;
dstr = name;
//while (sstr < nstr) {
while (1) {
if (sstr >= nstr) break;
*dstr++ = *sstr++;
}
*dstr = (char) 0;
printf("Name = %sn", name);
/* 다음은 정수형 의 비교를 보기 위한 프로그램 */
srand( (unsigned)time( NULL ) );
int iv1, iv2;
iv1 = rand();
iv2 = rand();
if (iv1 >= iv2)
iv1 = iv2;
return iv1;
}
우선 char 포인터의 비교를 보면 다음과 같이 기계어로 컴파일 된다. (VC++6.0)
; if (sstr >= nstr) break;
cmp eax, esi
jae SHORT $L1005 ; 만약 조건 만족하면 break
여기서 보면 2 포인터를 비교하기 위해 cmp라는 기계어 코드가 보인다. 이것은 두 레지스터의 값을 빼고 FLAG을 setting 하고 뺀 값은 버린다.
이것과 int의 비교를 보면
; if (iv1 >= iv2)
cmp esi, eax
여기서도 포인터와 마찬가지의 구성으로 코딩 된다.
그런가 하면
sstr++과 같은 포인터 증가는
inc eax
와 같은 기계어로 코딩 된다.
이와 같이 char의 포인터 뿐만 아니라 모든 포인터는 CPU의 레지스터와 ALU과 결합되어 정수처럼 계산된다.
char의 8비트 데이터 처리와 구조
char 변수는 단순히 string 처리만을 하는 것은 아니라 8비트 처리의 총체라고 이미 언급 했다. 이것은 다른 많은 데이터의 처리에서 문자가 아닌 숫자가 사용되는데 이것이 8비트라면 char을 사용하면 되는 것이다. 물론 숫자를 int로 처리할 수 있지만 메모리라든가 처리 속도 등을 고려하여 char을 사용할 수 있다. 그리고 struct와 연계하여 처리되어 질 때도 byte라는 개념이 들어가면 무조건 char 변수를 사용하면 된다. 만약 통신용 프로그램을 작성하려 할 때, 버퍼를 잡을 때 byte 단위로 char array로 잡고 struct로 포맷을 만들어 포인터 개념을 사용하여 프로그램 할 수도 있다.
예를 들어 두 시스템간 통신 프로그램 작성을 할 때, 통신 포맷이 존재한다. 이 포맷은 통신이 진행되면서 여러가지 역활을 하는데 메모리 입장에서 byte로 잡고 조작할 수 있다.
다음 형태의 포맷을 구성해 보면
FORMAT ST : DTYPE : LENGTH : DATA : CRC32
OCTET 1 1 2 가변(32비트 어래인지) 4
각 요소를 간단히 정의 하면
l ST : Start Code 0x03으로 정의
#define ST_CODE 0x03
l DTYPE : 다음에 나오는 데이터의 취급 방법 기술인데 다음과 같은 종류를 정의 한다.
#define DTYPE_RAW 1 ‐ BYTE 형태의 데이터
#define DTYPE_STRING 2 ‐ C의 string의 형태
#define DTYPE_INT 3 ‐ 정수형 32비트의 데이터의 나열이다.
목적에 맞는 설정을 하면 된다.
l LENGTH: 다음 부분부터의 데이터 길이를 정의한다. 단위는 바이트이다.
l DATA : DTYPE의 형태에 따라 데이터가 온다.
l CRC32 : 데이터의 조합이 맞는지를 검토하기 위한 32bit CRC
이를 프로그램 하기 위해 다음과 같은 struct을 정의할 수 있다.
#define ST_CODE 0x03
#define DTYPE_RAW 1 // BYTE 형태의 데이터
#define DTYPE_STRING 2 // C의 string의 형태
#define DTYPE_ID 3 // 정수형 32비트의 데이터의 나열이다.
// 다음의 각 비트 단위는 CPU 마다 다르므로 주의 해야 한다.
typedef unsigned int u32;
typedef unsigned short int u16;
typedef unsigned char u8;
typedef struct CPacket {
char startcode;
char dtype;
u16 length;
char data[4]; // 가변 길이 전송할 데이터
u32 crc; // CRC32
} CPacket;
이 struct 구조는 프로그램의 용이성과 패킷의 형태를 결정하여 만든다. struct을 구성할 패킷은 처음의 char 변수 2개로 16비트를 맞추고 다음 length로 16비트를 맞춘다. 그러면 앞에서 3개 변수가 32비트가 된다. 다음은 데이터가 들어가는데 이것의 길이는 가변이므로 4바이트로 정의한 것은 특별한 의미가 없고 데이터의 위치만은 나타내고 프로그램 할 때, 포인터 조작을 위한 것이다. 다음의 CRC32의 위치는 위의 변수가 가변의 길이이기 때문에 의미는 없고 단지 CRC32가 데이터 다음에 나온다는 표시를 시각적으로 한 것이다. 이 말은 패킷을 만들어 보아야 길이가 결정되고 length 변수와 함께 crc의 위치를 계산할 수 있다.
위의 예와 같은 경우는 개발자 임의 정의한 것인데 실제로 통신의 경우는 표준화 때문에 개발자 마음대로가 되지 않으므로 상황 맞추어 struct을 잡는다.
이를 이용하여 데이트를 조합하여 패킷을 만들면
char txBuff[1024];
int makePacketA(CPacket *pkt, char type, void *data, int leng)
{
int cnt;
int crcCalcLeng; // CRC32을 계산할 때 길이를 나타낸다.
pkt-> startcode = ST_CODE; // (1) Start Code 넣기
pkt-> dtype = type; // (2) 패킷 타입 결정
switch (type) {
case DTYPE_RAW : // 1 - BYTE 형태의 데이터
{
unsigned char *dt;
unsigned char *srct;
dt = (unsigned char *) pkt->data; // (3) 데이터 넣기
srct = (unsigned char *) data;
for (cnt = 0; cnt < leng;cnt++)
*dt++ = *srct++;
while (cnt & 0x0003) { // (4) 더미 데이터 넣기 - 32비트 어래인지,
// struct의 데이터 타입을 원할히 하기위해
*dt++ = 0;
cnt++;
}
pkt->length = (u16) (cnt // (5) data 길이 계산하여 넣기 – 가변 길이
+ sizeof(u32) ); // CRC 바이트
// (6) CRC32 계산 하기
crcCalcLeng = sizeof(char) // char startcode;
+ sizeof(char) // char dtype;
+ sizeof(u16) // u16 length;
+ cnt; // data length
*(u32 *)dt = (u32)fn_calc_memory_crc32((void *) pkt, crcCalcLeng);
printf("DTYPE_RAW : Data Length for CRC Calc.= %dn", crcCalcLeng);
return (int) crcCalcLeng + sizeof(u32); // (7) 패킷 전체 길이 return
}
. . .
이를 이용하여 데이트를 조합하여 패킷을 만들면
(1) Start Code 넣기
(2) 패킷 타입 결정
(3) 데이터 넣기
(4) 더미 데이터 넣기 : 32비트 어래인지를 한것인데, 이것은 struct의 데이터 타입을 맞추지 않는면 수신 측에서 struct을 사용하여 프로그램을 할 때 다음의 32비트 CRC을 4바이트를 비트 연산으로 32비트로 만들어야 하는 수고가 따른다.
프로그램과 처리속도를 고려하여 더미 데이터가 0~3바이트까지 들어간다. 대신 데이터의 통신을 해야하는 통신상의 더미를 더 보내야 하는 희생을 하여야 한다.
(5) data 길이 계산하여 넣기 – 이것은 데이터의 길이가 가변으로 설정하여 프로그램하기 때문에 포멧상 길이 데이터를 추가하였다.
(6) CRC32 계산 하기 : 여기에 사용된 CRC32는 Linux Kernel의 통신 프로그램 중에서 추출한 것이다.
(7) 패킷 전체 길이 return – 가변길이 이므로 중요하다.
이 패킷을 통신라인을 통해 보내면 다시 나누어 각각의 데이터를 분리하여 사용하면 되는데
char rxBuff[1024];
CPacket *pkt
U16 length;
char *data;
u32 crc;
pkt = (CPacket *) rxBuff;
. . .
length = pkt->length;
crc = pkt-> crc;
. . .
이와 같이 이용하면 되는데 여기서 주의 할 점은 CPU간 데이터 표시가 다르다는데 있다. 위에서 언급한 Big Endian과 Little Endian 문제이다. 만약 2개의 CPU가 각각 다른 endian 방식을 사용한다면 16,32,64 비트의 변수가 MSB와 LSB가 바이트 단위로 바뀌는 문제가 있다.
송신 측에서
pkt->length = length;
해서 보내면
수신 측에서
length = pkt->length;
할 때 2개의 CPU간에 뒤집히는 경우가 있다.
만약 송.수신 측의 길이가 0x0123일 때, 수신에서는 0x2301로 해석된다는 이야기 이다. 이것은 처음 설계부터 고려하여 포맷을 설정하고 통신하고 해석하는 설계를 해야 한다.

 C Runtime 환경의 메모리 릭 잡는 방법 (Memory leak)
C Runtime 환경의 메모리 릭 잡는 방법 (Memory leak)